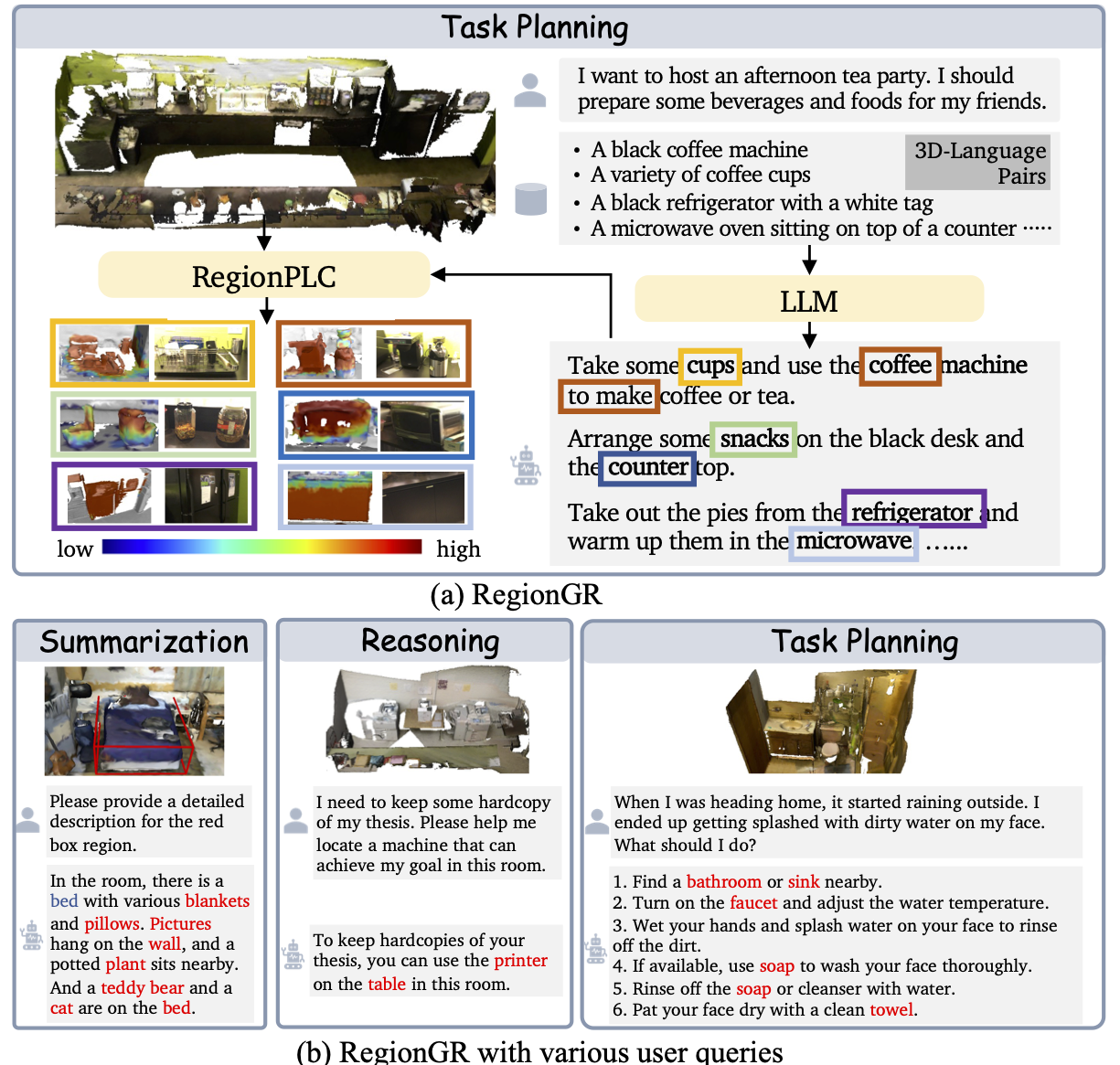
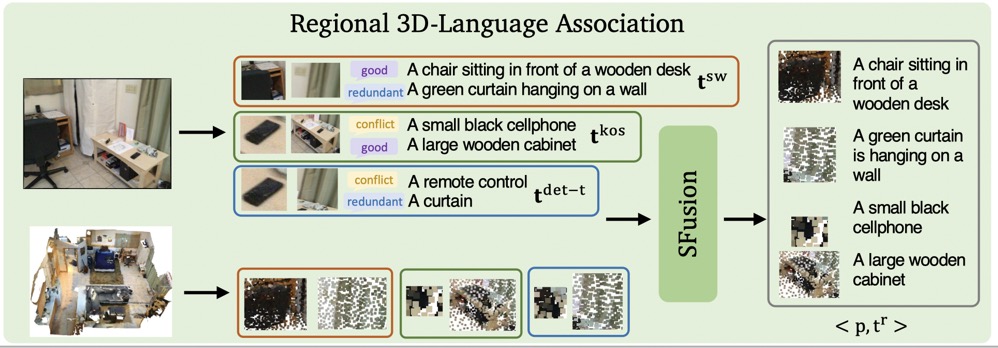
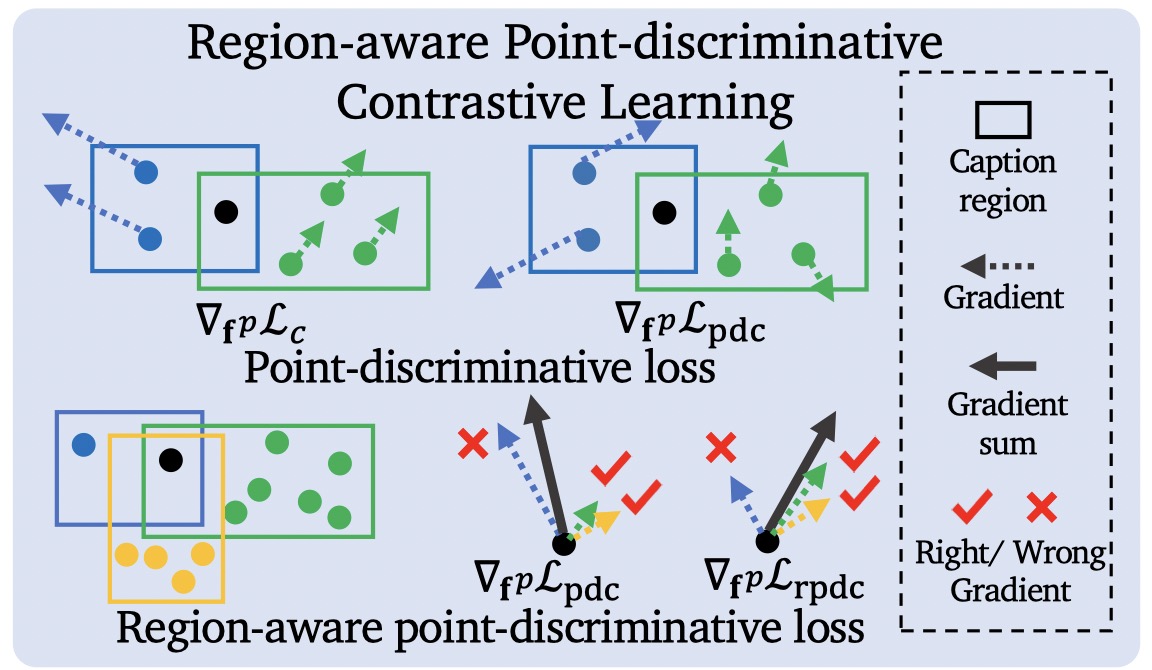
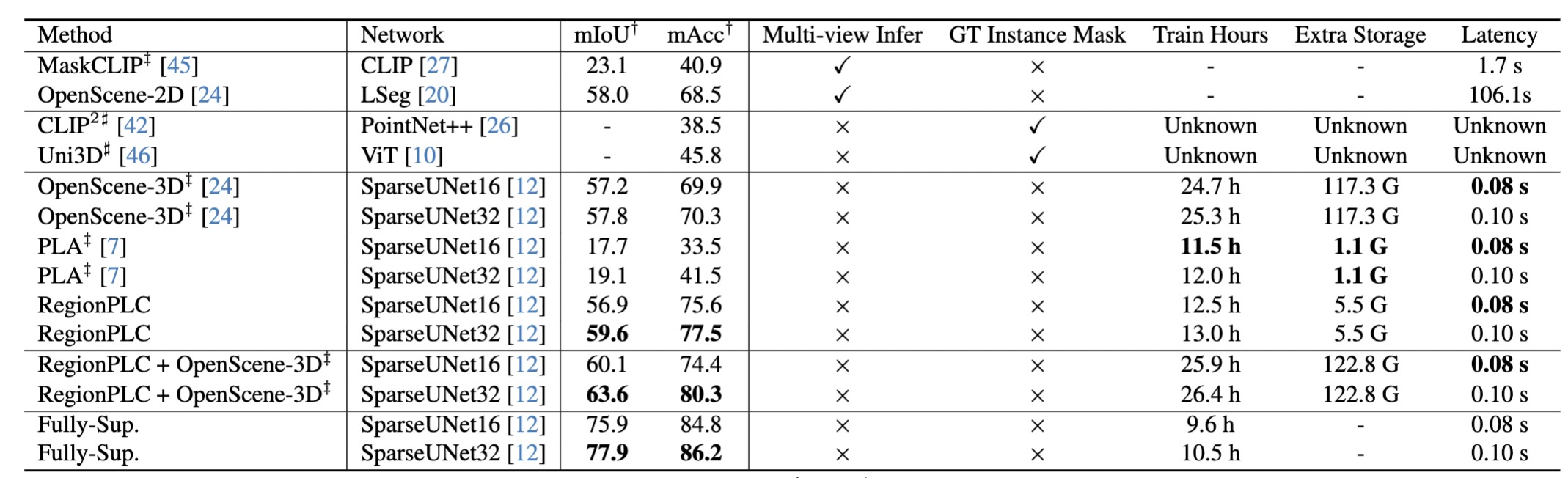
Novel Catgory Segmentation
|
Backpack
|
Keyboard
|
Pillow
|
Ladder
|



Novel Catgory Heatmap
|
paper
|
Keyboard
|
shoes
|
Trash Can
|




Grounded 3D Reasoning